【阿里云】2024年5月21日【算法岗暑期实习】面试经验分享
- 面试流程:1个小时多。
- 介绍WordEmbedding
- 线性回归和逻辑回归的区别
- 介绍 Information Gain(信息增益)IG
- 做情感分析的时候存在多义词应该如何解决?
- 解题思路一:
- 解题思路二:
- 解题思路三:
面试流程:1个小时多。
- 自我介绍
- 先看简历,介绍论文和项目,细细讲。
- 问NLP和机器学习与数据结构问题。
介绍WordEmbedding
Word Embedding 是一种将词语表示为低维稠密向量的方法,使得具有相似语义的词在向量空间中距离较近。这种方法通过捕捉词语之间的语义关系,广泛应用于自然语言处理任务中。以下是对 Word Embedding 的详细解释:
什么是 Word Embedding
Word Embedding 是将词语映射到连续向量空间的技术,这些向量通常是低维的(如100维或300维),相比传统的高维稀疏表示(如 one-hot encoding),它们更为紧凑且包含更多语义信息。
特点和优势
-
低维度:与 one-hot encoding 的高维稀疏向量(词汇表大小)相比,word embedding 是低维稠密向量(通常为几十到几百维)。
-
语义相似性:相似语义的词在向量空间中相近,例如 “king” 和 “queen” 的距离较近,且 “king” - “man” + “woman” ≈ “queen”。
-
自动学习:通过大规模语料库和特定的算法,word embedding 可以自动学习,不需要手工定义词语的特征。
常见的 Word Embedding 方法
-
Word2Vec:由 Google 提出,包括 Skip-gram 和 CBOW(Continuous Bag of Words)两种模型。Skip-gram 通过预测给定词语的上下文词语来训练,CBOW 则通过上下文词语预测中心词。
-
GloVe (Global Vectors for Word Representation):由 Stanford 提出,通过统计词对共现矩阵,并对其进行矩阵分解来训练词向量,捕捉全局词汇共现信息。
-
FastText:由 Facebook 提出,扩展了 Word2Vec 方法,考虑了词语内部的字符 n-gram,可以更好地处理未登录词和词形变化。
-
ELMo (Embeddings from Language Models) 和 BERT (Bidirectional Encoder Representations from Transformers):这类方法生成上下文相关的词向量,每个词的表示会根据其上下文变化,捕捉更深层次的语义关系。
应用
- 文本分类:将文本中的词转换为向量,然后使用这些向量进行分类任务。
- 机器翻译:将源语言和目标语言的词语表示为向量,利用向量进行语言间的转换。
- 信息检索:通过词向量计算相似度,改进搜索引擎的检索效果。
- 情感分析:利用词向量捕捉文本中的情感信息,进行情感分类。
总结
Word Embedding 是自然语言处理中的一种关键技术,通过将词语映射为低维稠密向量,有效捕捉词语之间的语义关系,广泛应用于各类 NLP 任务中。Word2Vec、GloVe、FastText 等方法提供了不同的实现思路,解决了高维稀疏表示的问题,推动了 NLP 领域的进展。
线性回归和逻辑回归的区别
线性回归和逻辑回归是两种常用的统计学习方法,尽管它们的名称相似,但它们适用于不同类型的问题,并有不同的模型假设和目标。以下是它们的主要区别:


通过以上对比可以看出,线性回归和逻辑回归在适用场景、模型形式和假设上有显著区别。理解这些区别有助于在实际问题中选择合适的模型。
介绍 Information Gain(信息增益)IG
信息增益是一个重要的概念,常用于特征选择和决策树构建中。它衡量的是某个特征对分类带来的信息增益,即在考虑某个特征后,数据的不确定性减少了多少。


示例
假设我们在文本分类任务中,有一个包含正面和负面评论的数据集。我们要选择一个特征(如一个单词)来划分数据集。我们计算每个单词的信息增益,选择信息增益最大的单词作为特征:
import math
from collections import Counter
def entropy(labels):
total_count = len(labels)
label_counts = Counter(labels)
return -sum((count / total_count) * math.log2(count / total_count) for count in label_counts.values())
def information_gain(dataset, labels, feature):
original_entropy = entropy(labels)
subsets = {}
for value in set(row[feature] for row in dataset):
subsets[value] = [labels[i] for i in range(len(dataset)) if dataset[i][feature] == value]
subset_entropy = sum((len(subset) / len(dataset)) * entropy(subset) for subset in subsets.values())
return original_entropy - subset_entropy
dataset = [
{'word': 'good', 'class': 'positive'},
{'word': 'bad', 'class': 'negative'},
{'word': 'good', 'class': 'positive'},
{'word': 'bad', 'class': 'negative'},
{'word': 'excellent', 'class': 'positive'}
]
labels = [item['class'] for item in dataset]
word_feature = 'word'
print(f"Information Gain for 'word': {information_gain(dataset, labels, word_feature)}")
这段代码计算了单词特征的信息增益,通过选择信息增益最大的特征来提高模型的性能。
总结来说,信息增益在 NLP 中是一个重要的度量,用于评估特征对分类任务的重要性,从而进行特征选择或决策树构建。
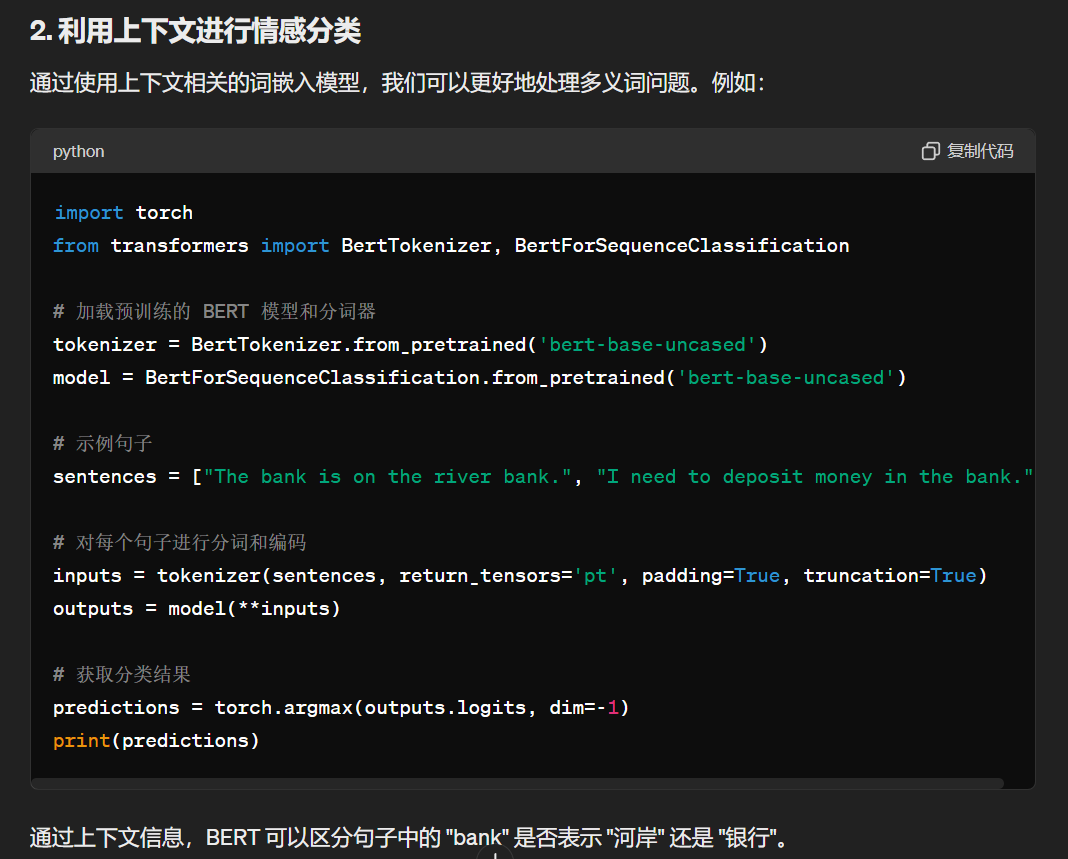
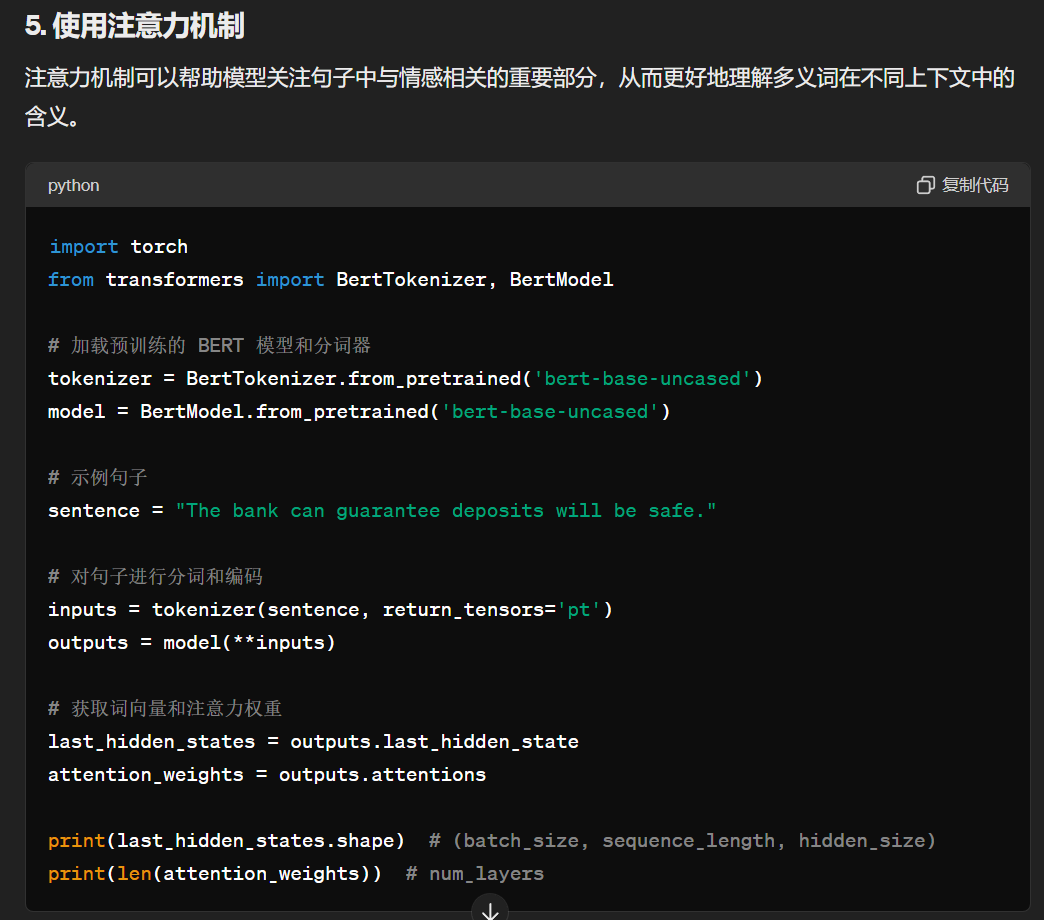
做情感分析的时候存在多义词应该如何解决?
在情感分析中,多义词(即一个单词在不同上下文中可能有不同的含义和情感极性)是一个常见且棘手的问题。为了解决多义词的问题,我们可以采用以下几种方法:


总结
解决情感分析中的多义词问题,关键在于利用上下文信息。上下文相关的词嵌入方法(如 ELMo 和 BERT)是目前最有效的手段。此外,结合领域知识、规则和注意力机制,可以进一步提高模型处理多义词的能力。在实际应用中,可以根据具体任务选择合适的方法或结合多种方法以达到最佳效果。
解题思路一:
时间复杂度:O(n)
空间复杂度:O(n)
解题思路二:
时间复杂度:O(n)
空间复杂度:O(n)
解题思路三:
时间复杂度:O(n)
空间复杂度:O(n)



♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠ ⊕ ♠